概述
21世纪10年代后,IDEA 凭借自身的各种优势逐渐取代传统 IDE,成为 Java 和 Kotlin 的首选开发环境,并且仍然在不断提升自身的魅力。
在 IntelliJ IDEA v2018.3 旗舰版之后,提供了新的实验性功能 JVM Profiler,目前适用于 macOS 和 Linux,而 Windows 的支持也在进行中。
下面,为大家介绍 JVM Profiler 的主要使用方式,以及 JVM Profiler 相比其他 Profiler 的优势在哪里。
介绍
开启
实验性功能的开启在 维护 里,首先打开维护对话框(快捷键,Linux 上的 Ctrl - Alt - Shift - /,macOS 上的 Cmd - Alt - Shift - /),选择 Experimental features 选项,然后勾选 idea.profiler.enabled 选项。
使用
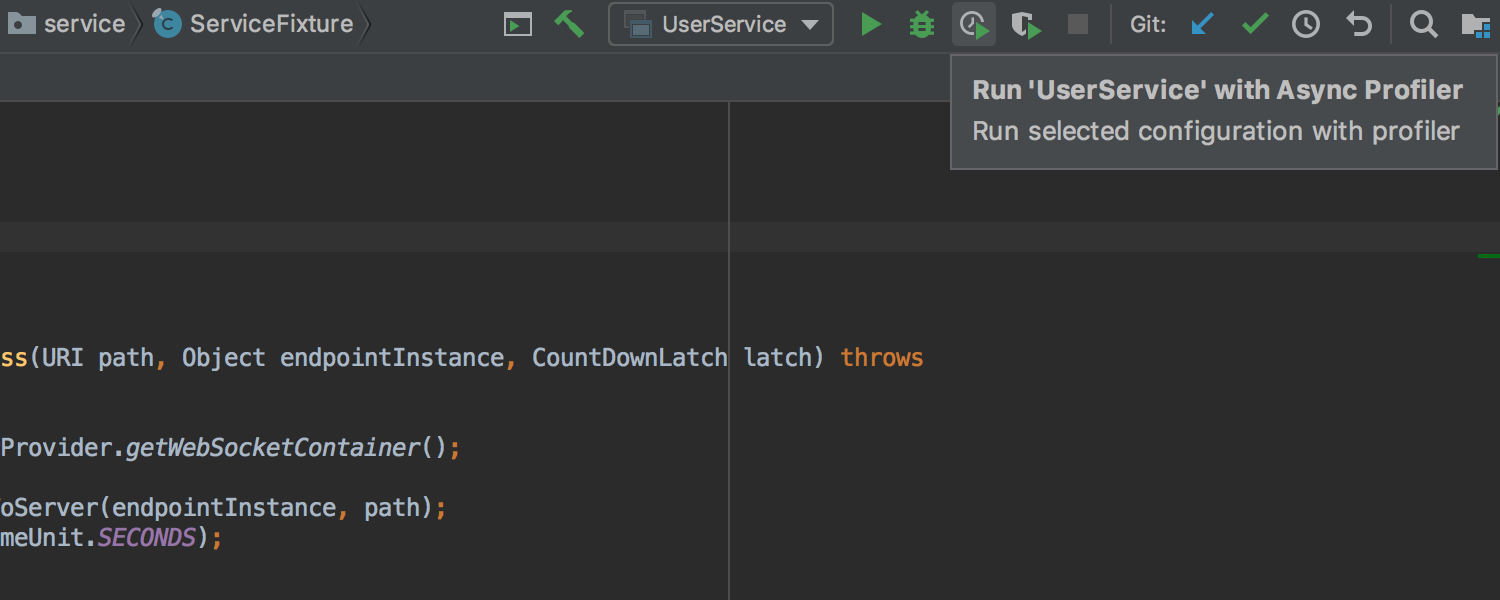
开启之后,工具栏 Run 右侧会出现 Run with Async Profiler ,使用该按钮启动即可:
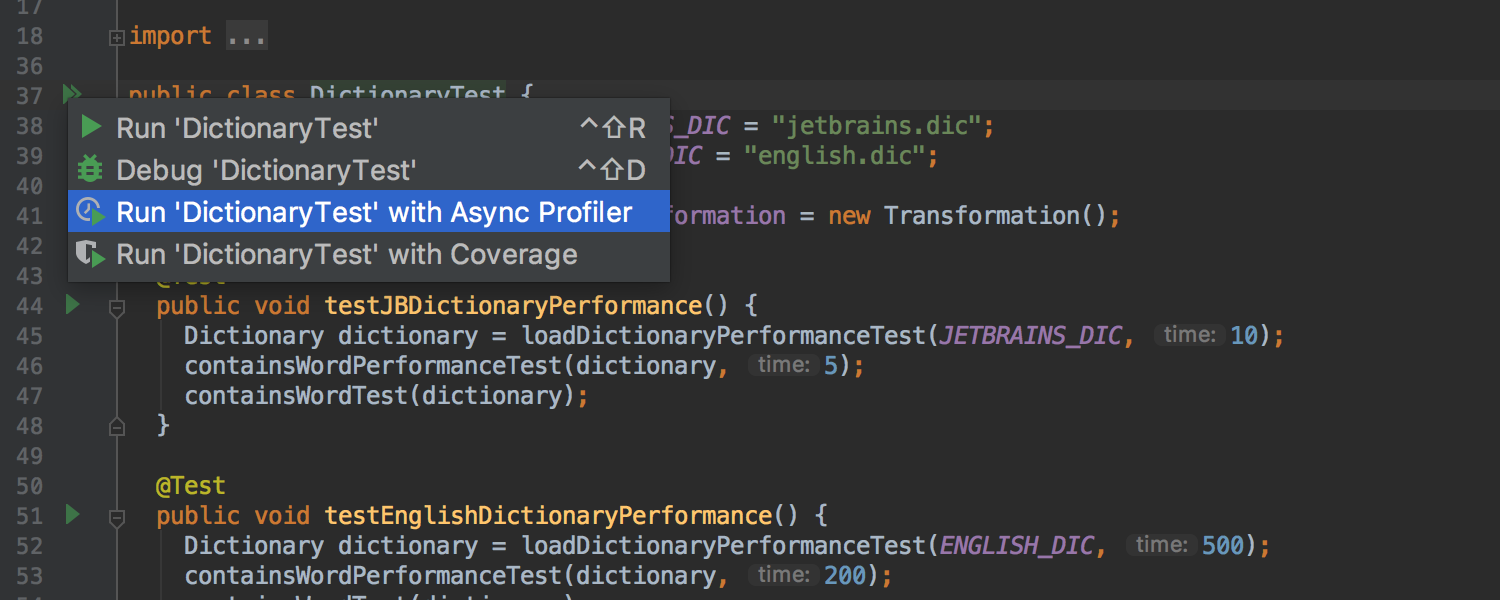
同样也支持单元测试:
JVM Profiler 主要功能
JVM Profiler 主要提供了 CPU Profiler 功能,Memory Profiler 在 2019.1 EAP 版中已经出现,这里主要介绍一下 CPU Profiler 功能。
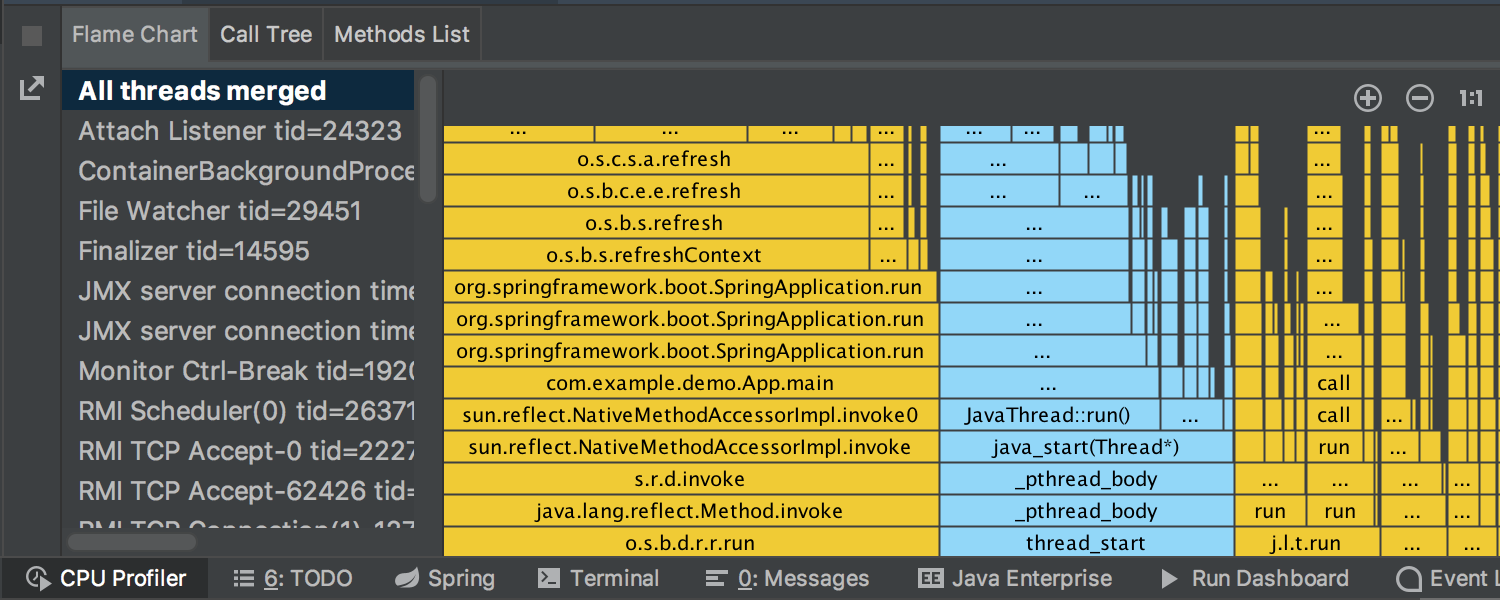
执行之后,工具窗口会新增 CPU Profiler,主要提供了:CPU 火焰图 Flame Graphs、调用树、方法列表,并且支持搜索、直接跳转到源码、转储等实用功能,包含 Java 和 Native 代码。
浅析
Profiler 的常见问题
Profiling 过程中数据的获取方式主要有抽样统计和附加指令的方式,前者的典型应用有商用应用 JProfiler、YourKit,后者有诸如阿里的 Tprofiler 等。这两种方式,均存在若干缺陷:
附加指令:会增加了性能开销;同时因为修改了程序代码,导致java编译器的优化行为不确定;同时影响了代码的层次,层次越深自然也影响执行效率;
抽样统计:获取系统范围的线程栈,JVM 必须处于 Safepoint 状态,只有当线 程处于 Safepoint 状态的时候,别的线程才能去获取它的线程栈,而这个 Safepoint 是由 JVM 控制的,这对于 Profiler 非常不利,有可能一个很热的代码块,JVM 不会在该代码块中间放置 Safepoint,导致 Profiler 无法获得该线程栈,导致错误的 Profiler 结果。
文章 Evaluating the Accuracy of Java Profilers,列举了xprof,hprof,jprofile 和 yourkit 四种采样器,并通过几个压测场景证明了这几种采样器的结果是相互矛盾的。总结的原因有:
附加指令:不同的采样器会注入不同的代码,从而影响程序优化过程,同时也影响了Safepoint 的分布,进一步造成采样差异;
抽样统计:采样器采样点不够随机,这几种采样器都只有在 Safepoint 采样。
JVM Profiler 实现原理
IDEA 的 JVM Profiler 并不存在上述问题。
IDEA 集成了低开销的采样分析器 async-profiler,可以分析 JVM 和 Native 代码,并且不会受到 Safepoint bias problem 的影响。
async-profiler 的基本原理是:AsyncGetCallTrace + perf_events,接收 perf_events 生成的调用堆栈,并将其与 AsyncGetCallTrace 生成的调用堆栈进行匹配,最终生成包含 Java 和 Native 代码的准确 Profiler 。
AsyncGetCallTrace
AsyncGetCallTrace 是 JVMTI 的一个非标准接口,Jeremy Manson 也通过其实现过简单的 Profiler 工具 Lightweight Asynchronous Sampling Profiler,
Jeremy Manson/Google 在文章中提及过通过用操作系统信号 SIGPROF 和 AsyncGetCallTrace 接口定时去采样堆栈,提升了采样准确率:
The benefit of using this interface to write a profiler is that it can gather stack traces asynchronously. This avoids the inaccuracies of only being able to profile code at safe points, and the overhead of having to stop the JVM to gather a stack trace. The result is a more accurate profiler that avoids the 10-20% overhead of something like hprof. For a more thorough explanation as to why this is interesting, see my 2010 writeup on the subject.
这种方式使用案例也有很多,如美团点评的 性能优化平台 scalpel、Oracle Developer Studio Performance Tools。
作为浅析,到这里就结束了,如果想更深入的了解细节,可以查看相关文章和开源代码。